LoRA Insights: PEFT Recipes
2024Reproducing and extending Sebastian Raschka's LoRA experiments across multiple models to find practical fine-tuning recipes. Ran hundreds of experiments on an H100 GPU comparing LoRA and QLoRA configurations, evaluating with EleutherAI's lm-evaluation-harness on tasks like TruthfulQA, arithmetic, and MMLU.
Models Tested
- Llama 3.2 3B
- Llama 3.2 1B
- Qwen 2.5 3B
Key Takeaways
- No magic LoRA config — significant experimentation is needed per model and use case
- Non-linear scaling — results do not improve linearly with increasing rank and alpha
- QLoRA memory savings — substantial reduction (~5.98 GB → ~2.05 GB model footprint) with only slight performance degradation
- All-layer LoRA helps, but not always — Llama 3.2 3B performed better with default target modules
- Recipes don't transfer — each model responds differently to the same config
- 1 epoch is enough — training beyond 1 epoch degraded performance in all tested cases
Evaluation
Models were evaluated using EleutherAI's lm-evaluation-harness on 6 tasks: truthfulqa_mc1, truthfulqa_mc2, arithmetic_2ds, arithmetic_4ds, blimp_causative, and mmlu_global_facts. Base model scores were compared against each fine-tuned variant to measure improvement or regression.
Experiment Setup
- Optimizer: AdamW
- Alpha: 2× rank (following Raschka's recommendation)
- Batch size: 32–64 depending on config
- Max sequence length: 512
- Hardware: H100 GPU on Ori Cloud (~$3.24/hr, ~$70 total experiment cost)
Memory Requirements
| Config | Model Footprint | Training Memory |
|---|---|---|
| LoRA (bfloat16) | 5.98 GB | 52.86 GiB |
| QLoRA (nf4) | 2.05 GB | 44.20 GiB |
Per-Model Observations
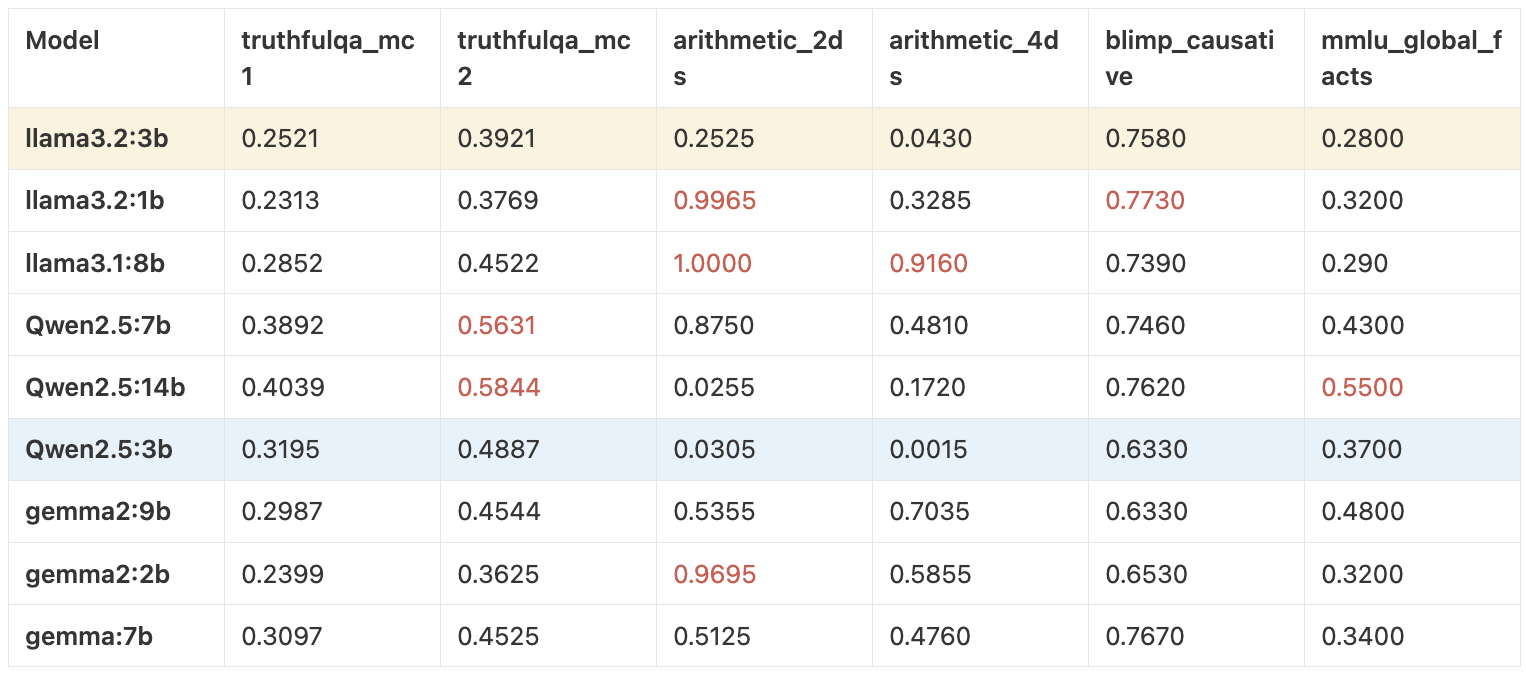
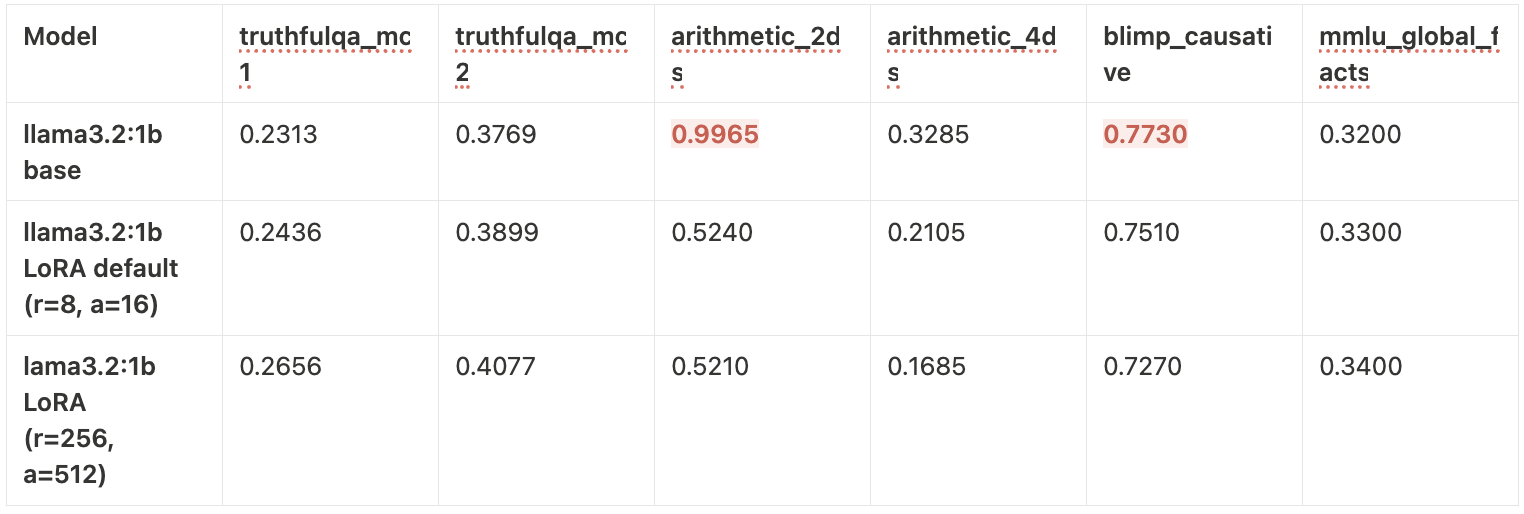
- Llama 3.2 3B: Best overall performer. Default LoRA target modules outperformed all-layer config. QLoRA close to LoRA quality.
- Qwen 2.5 3B: Benefited from all-layer LoRA. Showed larger variance across configs, making it harder to tune reliably.
- Llama 3.2 1B: Smaller model showed limited headroom. Fine-tuning gains were modest and inconsistent across tasks.
- Repository
- GitHub
- Platform
- H100 GPU (Ori Cloud)
- Stack
- PyTorch, TRL, PEFT, bitsandbytes, lm-evaluation-harness
- Dataset
- Alpaca Cleaned
Benchmark Results
Base Model Comparisons
Llama 3.2 3B — LoRA vs QLoRA
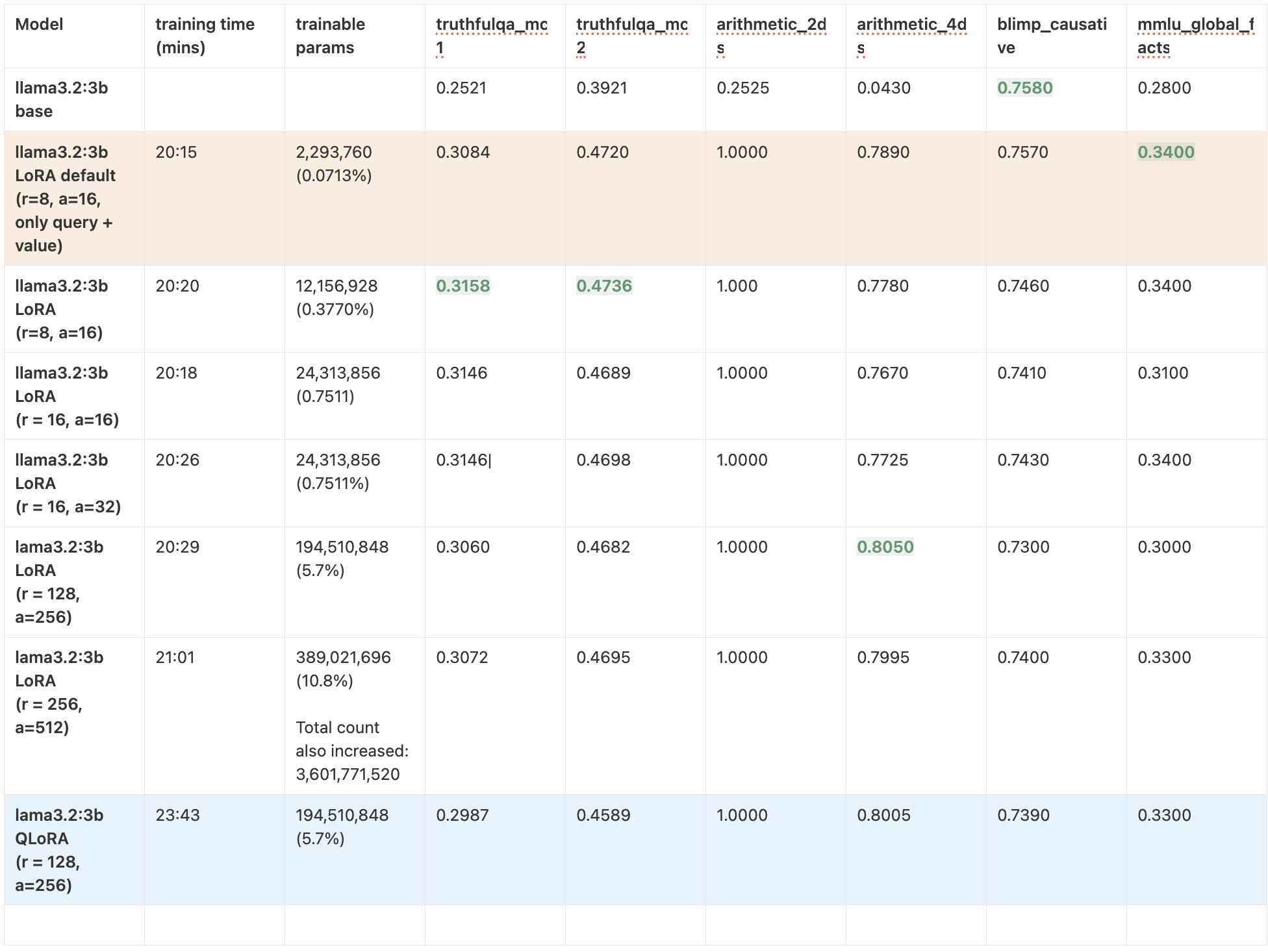
Qwen 2.5 3B
Llama 3.2 1B